Inside ClawRouter's Decision Layer: Real-Time Quality vs Cost
The most common question we get about ClawRouter is some version of: "How do you decide which model is the cheapest one that can handle the prompt?"
The honest answer is: we don't. That framing is a trap we tested in v0.12.47, and reverted from in 24 hours.
This is the technical story of how the decision layer actually works — what signals we read in real time, how a prompt maps to a tier, why fallback ordering matters more than primary selection, and how the system protects multi-step agentic workflows from a single bad routing decision.
It's a companion to our earlier post on benchmarking 46 models — that one covered the data underneath the system. This one covers what the system actually does with that data, request by request, in under a millisecond.
Why "Cheapest Sufficient" Is the Wrong Framing
In our v0.12.47 latency-first experiment, we promoted fast and cheap models to the top of every fallback chain. The COMPLEX tier looked like this:
// v0.12.47 — REVERTED after 24 hours
COMPLEX: {
primary: "xai/grok-4-0709", // 1,348ms, IQ 41
fallback: [
"xai/grok-4-1-fast-non-reasoning", // 1,244ms, IQ 41
"google/gemini-2.5-flash", // 1,238ms, IQ 20
// ... fast models first
],
}
Users complained immediately. Fast models with IQ 41 cannot reliably handle architecture design or multi-step code generation, no matter how cheap they are. A model that "can technically respond" to a hard prompt is not the same as a model that should.
The lesson became a hard-coded principle: optimizing for any single metric in a multi-objective system creates failure modes. You cannot optimize for cost without quality, or for quality without cost, or for either without latency. The decision layer has to optimize across all three simultaneously — and it has to do it before the request leaves the proxy.
The Decision, Step by Step
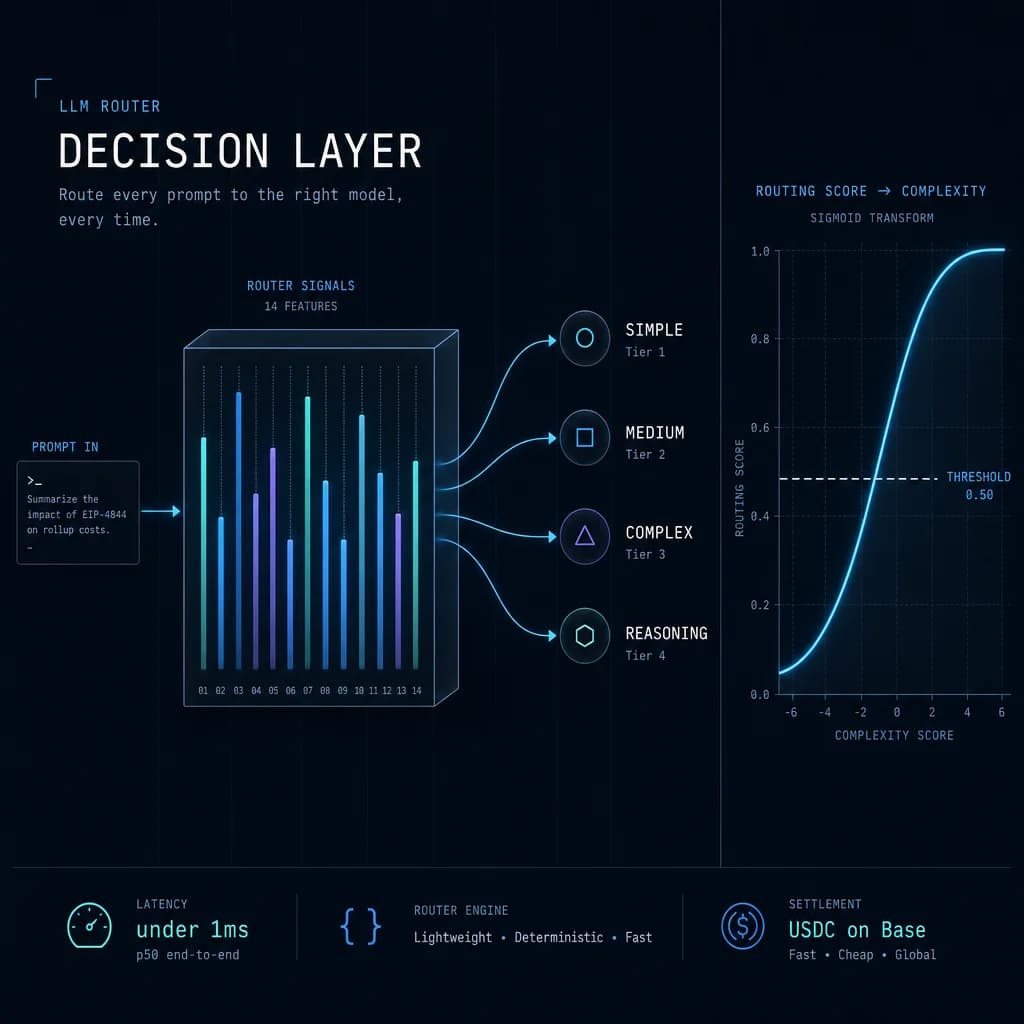
Every prompt that hits ClawRouter goes through five stages before a model receives it:
1. Lexical scoring → 15 weighted dimensions, score ∈ [-1, 1] each
2. Tier mapping → SIMPLE / MEDIUM / COMPLEX / REASONING
3. Confidence calibration → sigmoid; below 0.7 → AMBIGUOUS → default MEDIUM
4. Profile resolution → auto / eco / premium → primary + ordered fallback
5. Capability filtering → context window, tool calling, vision
The full pipeline runs in under 1ms on the proxy host. No external API calls. No LLM inference in the classification step. Pure keyword matching and arithmetic.
Stage 1: Fifteen Dimensions, Multilingual
The classifier reads the prompt and scores it across 15 weighted dimensions. Weights sum to 1.0:
| Dimension | Weight | Detects | Range |
|---|---|---|---|
| reasoningMarkers | 0.18 | "prove", "theorem", "step by step" | 0 to 1.0 |
| codePresence | 0.15 | "function", "class", "import", backticks | 0 to 1.0 |
| multiStepPatterns | 0.12 | "first…then", numbered lists, "step N" | 0 or 0.5 |
| technicalTerms | 0.10 | "algorithm", "kubernetes", "distributed" | 0 to 1.0 |
| tokenCount | 0.08 | <50 tokens vs >500 tokens | -1.0 to 1.0 |
| creativeMarkers | 0.05 | "story", "poem", "brainstorm" | 0 to 0.7 |
| questionComplexity | 0.05 | >3 question marks | 0 or 0.5 |
| agenticTask | 0.04 | "edit", "deploy", "fix", "debug" | 0 to 1.0 |
| constraintCount | 0.04 | "at most", "within", "O()" | 0 to 0.7 |
| imperativeVerbs | 0.03 | "build", "create", "implement" | 0 to 0.5 |
| outputFormat | 0.03 | "json", "yaml", "table", "csv" | 0 to 0.7 |
| simpleIndicators | 0.02 | "what is", "hello", "define" | 0 to -1.0 |
| referenceComplexity | 0.02 | "the code above", "the API docs" | 0 to 0.5 |
| domainSpecificity | 0.02 | "quantum", "FPGA", "genomics" | 0 to 0.8 |
| negationComplexity | 0.01 | "don't", "not", "avoid", "except" | 0 to 0.5 |
Every keyword list ships in 9 languages — EN, ZH, JA, RU, DE, ES, PT, KO, AR. A Chinese user asking "证明这个定理" triggers the same reasoning classification as "prove this theorem." Routing intelligence is not English-only.
Stage 2: Tier Mapping
The weighted score lands on a single axis with three boundaries:
SIMPLE < 0.0 < MEDIUM < 0.3 < COMPLEX < 0.5 < REASONING
That's the entire tier system. Each tier corresponds to a benchmarked floor of capability — we know from running 46 models through real workloads that any model in a tier's primary or fallback list will reliably handle requests that score into that tier.
This is the biggest framing difference from "cheapest sufficient." We're not searching for a model. We're classifying a request. Tier first, model second.
Stage 3: Sigmoid Confidence Calibration
What happens when a score lands near a boundary? A request scoring 0.31 is technically COMPLEX, but it's only 0.01 above the MEDIUM boundary. We don't trust that signal.
The router runs sigmoid calibration on every classification:
confidence = 1 / (1 + exp(-12 × distance_from_boundary))
Where distance_from_boundary is the score's distance to the nearest tier boundary. Steepness is fixed at 12, mapping confidence into a [0.5, 1.0] range. If confidence drops below 0.7, the request is reclassified as AMBIGUOUS and defaults to MEDIUM — not SIMPLE.
We deliberately fail upward, never downward. Under uncertainty, we'd rather spend a bit more than ship a bad result. This single mechanism is the largest insurance policy in the system, and it's why the COMPLEX-tier failure mode of "router gambled on a cheap model and lost" essentially doesn't exist for us.
Stage 4: Profile × Tier → Primary + Fallback Chain
Once a tier is locked in, we map (tier × user-selected profile) to a primary model and an ordered fallback chain. There are four profiles:
auto— default. Multi-objective: balances quality, cost, and latency from benchmark data plus retention metrics.eco— ultra cost-optimized. Uses free and near-free models where capability allows.premium— best quality regardless of cost.free— always uses free NVIDIA models. For development and testing.
The auto profile, tuned from real user retention data, looks like this:
SIMPLE → gemini-2.5-flash (1,238ms, IQ 20, 60% retention)
MEDIUM → kimi-k2.5 (1,646ms, IQ 47, strong tool use)
COMPLEX → gemini-3.1-pro (1,609ms, IQ 57, fastest flagship)
REASON → grok-4-1-fast-reasoning (1,454ms, $0.20/$0.50)
Note the SIMPLE choice. Gemini 2.5 Flash has IQ 20 — far from the smartest model — but it has the highest retention rate of any model we've tested for simple queries. Users keep coming back. That's a real, observable success metric, not a synthetic benchmark, and we trust it more than our prior assumption that "smarter = better."
Stage 5: Quality-First Fallback Chains
The primary handles the happy path. The fallback chain handles reality — rate limits, provider outages, payment failures, transient 5xx errors. Fallback ordering matters more than primary selection, because in production, the primary fails far more often than people assume.
Our fallback chains descend by quality first, then trade quality for speed. Here's the COMPLEX-tier fallback in auto:
fallback: [
"google/gemini-3-pro-preview", // IQ 48, 1,352ms
"google/gemini-3-flash-preview", // IQ 46, 1,398ms
"xai/grok-4-0709", // IQ 41, 1,348ms
"google/gemini-2.5-pro", // 1,294ms
"anthropic/claude-sonnet-4.6", // IQ 52, 2,110ms
"deepseek/deepseek-chat", // IQ 32, 1,431ms
"google/gemini-2.5-flash", // IQ 20, 1,238ms
"openai/gpt-5.4", // IQ 57, 6,213ms — last resort
]
GPT-5.4 sits last despite having the highest IQ in the list, because its 6.2-second latency creates a worse compounded experience across multi-step workflows than a slightly-lower-IQ model that completes in 1.4 seconds. We chose user experience over benchmark-purity. That's a quality decision, not a cost decision.
Stage 6: Runtime Capability Filtering
Before any model is dispatched, the candidate set is filtered against three hard constraints:
- Context window fit. Models whose context window can't hold (input + estimated output) × 1.10 safety buffer are removed.
- Tool calling. If the request includes tool definitions, only function-calling models stay in the chain.
- Vision. If the request includes images, only vision-capable models stay.
If filtering eliminates every candidate, we fall back to the unfiltered chain (better to let the API return a clear error than silently degrade). If a "cheaper" model lacks a required capability, it's removed from the candidate set, never silently substituted. This prevents the classic multi-step failure mode where a tool-call step gets routed to a model that can't actually call tools.
Per-Request x402 Isolation
One architectural property worth calling out explicitly: ClawRouter's per-request x402 payment model means every request is its own settled transaction. There is no session state to corrupt.
A provider failure on step 7 of a 20-step workflow doesn't cascade. The proxy walks the fallback chain in isolation for that single request, settles the call, and the workflow continues. Compare this to the cascading-failure stories we see in OpenClaw's native router on GitHub — Claude API → fallback to GLM-4.7 → endpoint error → fallback to Groq → rate limited → fallback to local Ollama. Single-session state shared across many calls. The classic stale-session-state problem doesn't exist for us, because we don't have sessions.
The Signals We Evaluate, in Real Time
Here's the full set of signals the decision layer reads on every request:
| Signal | Source | Used For |
|---|---|---|
| Intelligence Index (IQ) | Artificial Analysis v4.0 — composite of GPQA, MMLU, MATH, HumanEval | Quality floor per tier |
| End-to-end latency | Our own benchmarks across 46 models, 8 providers, through full x402 pipeline | Fallback ordering, tier eligibility |
| Token throughput | Same benchmark suite | UX-aware fallback ordering |
| Per-token pricing | Live provider rate cards | Cost estimate, profile assignment |
| Provider health | Real-time observability — error rates, 402/429/5xx classification | Fallback walk |
| User-retention rate per (tier × model) | Our own production usage data | Auto-profile defaults |
| Confidence calibration distance | Sigmoid on tier-boundary distance | AMBIGUOUS → MEDIUM defaulting |
| Capability flags | Per-model registry — context window, function calling, vision | Hard runtime filter |
Every routing decision returns a cost estimate and a savings percentage benchmarked against Claude Opus 4.6 as the "always premium" baseline:
savings = max(0, (opusCost - routedCost) / opusCost)
For a typical SIMPLE request (500 input tokens, 256 output tokens):
- Opus cost: $0.0089 (at $5.00 / $25.00 per 1M tokens)
- Gemini Flash cost: $0.0008 (at $0.30 / $2.50 per 1M tokens)
- Savings: 91%
Median savings across our user base is ~85% versus blanket Opus routing. That savings comes from routing the 60–70% of requests that genuinely don't need flagship intelligence to the right tier — not from gambling on the wrong model for the hard requests.
Why This Architecture, and Where It's Going
Three forces are reshaping where the decision layer is headed:
1. Gas-free settlement makes model-cost gaps sharper, not flatter. Today, x402 settlement overhead (50–100ms + minor gas) compresses the effective cost gap between a $0.20/M model and a $5.00/M model. Once Circle nanopayments goes live (April 13, 2026 co-launch), that floor disappears, and the cost differential between models becomes the dominant economic variable. The router has to be smarter, not lazier.
2. Agents have principals; principals have utility functions. When an autonomous agent runs unattended, the human or org behind it cares about expected utility per dollar, not the cheapest single-call price. A coding agent that picks a $0.20 model and produces a broken PR costs the principal a code-review cycle — orders of magnitude more than the saved inference cost. ClawRouter's roadmap moves toward per-agent budget envelopes with outcome feedback: each agent runs against a budget ceiling and a quality floor, and the router learns from success / retry / escalation signals which tier each workflow class actually needs.
3. Per-agent cost attribution is the missing primitive. Claude Code's cost-tracker.ts has no agentId parameter — every agent's cost flows into one global accumulator. Per-agent budgeting is architecturally impossible inside Claude Code today. BlockRun fills that gap with per-agent wallets (MVP shipping Q2 2026, before COORDINATOR_MODE GA). Once that primitive exists, the routing layer optimizes for the agent's policy, not a global heuristic.
Where the decision layer is going specifically:
- Outcome-aware reinforcement. Today the 15-dimension classifier is rule-based. Next-generation routing layers in user-success signals — retry rates, tool-call success rates, downstream verifier judgments — to refine tier assignment per workflow class. The router learns that "agentic refactor of a 10-file Python service" needs Claude Sonnet 4.6 even when the immediate prompt looks short.
- Budget-aware fallbacks. Fallback chains become budget-aware. High-budget agents get fallbacks that walk up the quality curve (Sonnet → Opus). Low-budget agents get fallbacks that walk down toward sustainable cost (Gemini Flash → Gemini Flash Lite). One fallback policy per agent profile.
- Verifier-in-the-loop for high-stakes calls. For financial, on-chain, or production-deployment agent calls, the router will optionally run a cheap second-model verification on the primary's output. Two cheap calls are often higher-utility than one premium call, and the verifier pattern catches single-model hallucinations that any single-model routing strategy misses.
What We Won't Do
We won't ship a router that picks "the cheapest model that can handle the prompt." We tried it. It breaks. The honest production architecture is:
- For low-stakes traffic — research, summarization, classification — the layer optimizes aggressively for cost, because the marginal IQ point doesn't change the outcome.
- For agentic, multi-step, tool-using, or financially-consequential traffic, the layer optimizes for maximum quality within budget, because a single suboptimal decision compromises the whole workflow and the savings on the bad call are dwarfed by the cleanup cost.
The role of the decision layer isn't to choose between cost and quality. It's to make sure neither dimension gets optimized in a vacuum — and to make that tradeoff explicit, configurable, and accountable per agent.
Appendix: Source
- Routing config:
src/router/config.ts - Scoring implementation:
src/router/rules.ts - Benchmark dataset:
benchmark-merged.json - ClawRouter docs: blockrun.ai/docs/products/routing/clawrouter
- Benchmarking deep-dive: LLM Router Benchmark — 46 Models, 8 Providers, Sub-1ms Routing